
Power BI Field Parameters en Calculation Groups
In deze blog kijken we eens naar de nieuwe functies Field parameters en Calculation Groups in Power BI en hoe we deze zowel in Power Desktop als in Tabular Editor kunnen gebruiken.

Tabular Editor Best Practice Analyzer
Tabular Editor is een veel gebruikte tool om semantische modellen te bewerken. Dit is al in verschillende blogs naar voren gekomen. Er bestaan natuurlijk veel best practices voor het ontwikkelen van een model. Maar hoe toets je deze regels nu op je model. Binnen Tabular Editor is de Best Practice Analyzer beschikbaar. Ook wel BPA genoemd. Met deze tool kun je vooraf gedefineerde regels toetsen en toepassen op je model.

SAP BO 4.3 tips & trucs
Er is al veel gezegd en geschreven over SAP BusinessObjects 4.3 en inmiddels hebben we al behoorlijk wat klanten geholpen bij het migreren naar SAP BusinessObjects 4.3. In deze blog zullen we eens kijken naar belangrijkste nieuwe functionaliteiten en zullen we tips delen over de migratie. Ook zullen we eens kijken hoe SAP BO 4.3 in samenwerking met Power BI gebruikt kan worden.
Toekomst van SAP BO
Er is een tijd geweest dat er onduidelijk was over de toekomst van SAP BusinessObjects, maar er is inmiddels alweer een tijdje terug aangekondigd dat na SAP BusinessObject 4.3 er ook weer een nieuwe versie komt in 2025, die dan weer minimaal 7 jaar ondersteund wordt. De laatste informatie hierover is terug te vinden in de SAP Analytics Business Intelligence Statement of Direction.
Redenen om over te stappen naar SAP BO 4.3
Er kunnen verschillende redenen zijn om over te stappen naar SAP BI 4.3. Naast de nieuwe features waarvan een aantal in de volgende paragraaf wat meer uitgelicht zijn, worden vaak ook de volgende redenen genoemd dat men besluit tot overgaan van een upgrade:
- End Of Support van SAP BO 4.2 (prio 1 support patches beschikbaar t/m eind 2023, laatste Service pack was in 2022).
- End of (mainstream) van het besturingssysteem, bijvoorbeeld Windows 2012 & 2016.
- End of Support van gebruikte databases. Bij een (geplande) upgrade van een database kan het zomaar zijn dat dit niet ondersteund wordt door een verouderde versie van BusinessObjects.
- Security redenen. In de meeste setups maakt SAP BusinessObjects gebruik van Tomcat als webserver, dat meegeleverd wordt bij de installatiebestanden. Er kunnen kwetsbaarheden in Tomcat zitten en het is daarom aan te bevelen om regelmatig deze site van Tomcat te controleren en de impact in te schatten. Niet alle security issues van Tomcat hebben impact op de Businessobject omgeving. Controleer daarom ook altijd SAP note 2498770.

Nieuwe functionaliteit in SAP BI 4.3
De meest in het oog springende nieuwe functionaliteit van SAP BI 4.3 is het Fiori Launchpad. Deze nieuwe interface voor het bekijken van rapporten was al te activeren in de laatste versies van BO 4.2, maar in versie 4.3 is deze nog verder uitontwikkeld en wordt deze nieuwe interface ook gebruikt bij het ontwikkelen van rapporten. Overige nieuwe features die het benoemen waard zijn:
Data Mode (Data Preview)
Vergelijkbaar met de Rich Client van versie 4.2 waar je de queryresultaten kon zien in ruwe vorm. Dit maakt het makkelijker om te kijken of je query de gewenste resultaten ophaalt en hoef je niet gelijk met bouwen te beginnen zonder dat je zeker weet of je query juist is. Deze “Data Mode” kent ook nieuwe functionaliteit (vanaf 4.3 SP3) zoals grafische weergave van de datasources met herkomst en aantal records, wat weer handig is voor het overzicht bij gebruik van meerdere datasources in je rapport. Ook de “Facet view” zoals hieronder afgebeeld geeft extra analyse mogelijkheden voor queryresultaten. In versie 4.3 SP4 is er zelfs de mogelijkheid om in “Data Mode” virtuele cubes te creëren. Hiermee kan je datasources uit verschillende universes (of andere bronnen) combineren door ze met elkaar te joinen op de dimensies die jij aangeeft. Dit mogelijkheid om het type join (Full, inner, right, left) aan te geven maakt dit flexibel. Nieuwe virtuele cubes kan je ook weer op deze manier met elkaar combineren. Hiermee kan je uiteindelijk tot een dataset komen, die je gebruikt voor het maken van je rapportages of je stelt deze dataset (als OData) beschikbaar voor andere om daarop een rapport te bouwen. De oude manier om datasources in je rapport aan elkaar te koppelen via “Merge Dimensies” is nog steeds aanwezig, maar in complexere situaties kan dit een mooie manier zijn om een superset te creëren.


OData APIs
Met OData APIs (OData Web Service) kan je een WebI rapport boven op een andere Webi rapport bouwen. Dat andere WebI rapport kan een virtuele cube zijn zoals hierboven beschreven of het kan een dataprovider uit een ander WebI rapport zijn, maar het is ook mogelijk een tabel vanuit een WebI rapport als input voor een nieuw WebI rapport te gebruiken. Dit laatste kan weer handig zijn als het een tabel is met variabelen erin die je wil hergebruiken. OData APIs ter beschikking stellen kan handig zijn voor gebruikers die wel rapporten willen bouwen, maar het proces om tot een goede dataset te komen lastig is.
Microsoft Drive
Vanaf 4.3 SP3 is schedulen naar Microsoft Onedrive of SharePoint mogelijk. Steeds meer bedrijven maken gebruik van Onedrive en SharePoint en sommige bedrijven nemen dan helemaal afscheid van hun Fileserver. Een eenmalige configuratie in het Central Management Console is wel nodig om dit werkend te krijgen. Voor meer details over nieuwe functionaliteiten kan je ook de blog reeks van SAP bekijken. De details over nieuwe features van 4.3 SP3 vind je hier en 4.3 SP4 vind je hier hier.

Tips & trucs voor upgrade naar SAP BO 4.3
Een upgrade naar SAP BO 4.3 kan best wel complex zijn, vooral als er nieuwe servers neergezet worden en alles opnieuw geconfigureerd moet worden. Een goed startpunt is de Product Availability Matrix (PAM) hierin is aangegeven per SAP BO service pack welke product versies hier allemaal compatibel mee zijn. Denk hierbij aan besturingssystemen, cloudplatformen (bijv. Azure) en database types en versies. Een ander belangrijk document als voorbereiding is de Sizing guide. Hiermee kan je beter bepalen aan welke “sizing” de BO server moet voldoen of dat er misschien wel geclusterd moet worden. Over het algemeen is het wel zo dat als de performance van de huidige BO 4.2 omgeving goed is deze “sizing” ook overgenomen kan worden voor versie 4.3. Controleer ten slot of alle BO componenten die je in de huidige versie gebruikt nog beschikbaar zijn in versie 4.3 (sap note 2801797). Hieronder nog een aantal specifieke tips voor de upgrade naar SAP BI 4.3
- SAP BI 4.3 vereist nieuwe licentie keys. Probeer deze tijdige voor de start al te downloaden van de SAP-site. Het komt wel is voor dat juiste credentials niet meer voorhanden zijn en opnieuw aangevraagd moeten worden bij SAP.
- Client tools zoals bijvoorbeeld Information Design Tool zijn nu 64-bits er zijn nu dus ook 64- bits database drivers nodig.
- Het serviceaccount waaronder BO in de oude versie draait kan worden hergebruikt. Dit voorkomt dan eventueel problemen met allerlei rechten dat dit account heeft.
- Voor configuratie van Windows Active Directory (AD) en Single Sign On (SSO) volg SAP note 2629070 en tegenwoordig is het ook niet meer nodig om de domainserver(s) op te nemen in de krb5.ini file, wat weer toekomstig onderhoud scheelt. Zie ook laatste alinea van SAP note 1245178.
- Het wordt steeds meer best practise om firewalls tussen servers in te regelen. Definieer deze poorten in de CMC onder servers en reserveer poorten 6400 tot en met 6430 hiervoor. Let op 6400, 6405 en 6410 zijn al standaard in gebruik door BO. Poort 80 (http) en 443 (https) kunnen gebruikt worden voor de webserver.
- Configuratie van SSL (HTTPS) voor Tomcat is ook een wens die steeds vaker voorkomt. Hiervoor heb je wel nieuwe certificaten nodig die aangemaakt zijn op basis van het intranet domein en servernaam (of DNS). Zie ook SAP note 1648573 en voor redirect van HTTP verkeer naar HTTPS zie SAP note 1730321.
- Voor het overzetten van content (gebruikers, rechten, rapporten, universes, ect.) zijn er verschillende manieren om dit te doen. Je kan de promotiemanagement wizard gebruiken die mee geïnstalleerd wordt op de BO server (let vooral op memory settings en schijfruimte), LCM command line tool gebruiken of promotion management in het CMC. Mijn persoonlijke voorkeur is de laatste, omdat ik het makkelijker in stappen kan doen en meer controle kan uitvoeren. Zet wel de audit tijdelijk uit in de oude en nieuwe versie via CMC dat scheelt behoorlijk in performance.
- Bij het overzetten van schedules en publicaties is het handig om de jobserver te stoppen en een tijdelijke te maken die alleen de (sub) services bevat voor promotionmanagement. Dit voorkomt dat schedules meteen beginnen te draaien nadat deze zijn overgezet.
- Vanaf 4.3 (en 4.2 SP9) is een whitelist nodig bij het schedulen van rapporten naar een fileshare, wanneer deze whitelist er niet is of de betreffende locatie is niet aanwezig in de whitelist dan zal de schedule een foutmelding geven. Zie ook SAP note 3249645.
- In 4.3 zijn een paar rechten anders dan in versie 4.2, waar je vooral last van kan hebben als er gebruik gemaakt wordt van Custom Access Levels. O.a. Export report data to Excel, pdf, txt is samengevoegd in een nieuw recht “Export the report's data” en zal moeten worden toegekend aan het betreffende Custom Access Level anders werken deze rechten niet meer. Hetzelfde geldt voor het recht “Logon to the new Fiorified BI Launch pad” wanneer deze niet in het Custom Access Level staat kunnen mensen niet meer inloggen in de 4.3 versie. Zie ook SAP notes 3028997 en 2627502.
Combi met Power BI
Power BI is een tool die steeds vaker gebruikt wordt en we helpen ook veel klanten met de inrichting van hun Power BI architectuur. De best practise voor een Power BI architectuur is te werken met Power BI datasets (semantic model) in combinatie met een Power BI premium (per user) licentie. Wanneer je echter een “lightweight” oplossing zoekt om Power BI met data uit SAP BusinessObjects te laten werken dan bieden de nieuwe features van BO 4.3 uitkomst. Het doel is dan om de meest actuele data uit BusinessObjects automatisch in Power BI service (powerbi.com) te updaten. Dit kan door de OData feature van 4.3 te gebruiken zoals hierboven beschreven staat. Ook de ouderwetse manier schedule naar fileserver in Excel formaat is mogelijk, zolang dit maar een leesbaar formaat in tabel vorm oplevert. Voor beide geldt wel dat de OData URL en of de fileserver locatie gedefinieerd moet worden in de On-premises data gateway. De nieuwe mogelijkheid om te schedulen naar een Microsoft Drive heeft als voordeel dat er geen Gateway nodig is, omdat Power BI dat afhandelt via de Cloud credentials. Wel is altijd minimaal Power BI Pro nodig, maar vaak al beschikbaar als onderdeel van Microsoft 365 E5. Zie in onderstaand plaatje ook de mogelijkheden om BO data te hergebruiken in een Power BI oplossing.

Conclusie
Met een upgrade naar SAP BI 4.3 profiteer je van de nieuwste features, connectiviteit en ben je weer verzekerd van support. Ook kan je na 4.3 weer rekenen op een nieuwe versie met on-premise uitrol mogelijkheden. Overweeg je toch een volledige overstap naar Power BI dan kunnen we hierin ondersteunen.

Ad-hoc analyse met Power BI Explore
Vaak willen gebruikers snel ad-hoc analyses maken van data in een Power BI model of ze willen bijvoorbeeld het model verkennen voordat ze daadwerkelijk rapportages gaan maken. Dat is nu mogelijk met de nieuwe functie "Explore" binnen de Power BI Service (public preview).

De explore functionaliteit is beschikbaar op rapporten, datamarts en semantische modellen. De explore functionaliteit kan gestart worden door op "..." te klikken bij een model, rapport of datamart. Als deze functionaliteit wordt gebruikt op een rapport wordt gewoon de explorer van het onderliggende semantische model gestart.
Via de explore functionaliteit kan dan simpel en snel een analyse worden gemaakt zonder dat er een apart rapport voor gemaakt moet worden. Het voordeel boven een rapport is dat je de mogelijkheid hebt om de data gelijk in een matrix en een visual naast elkaar te zien.

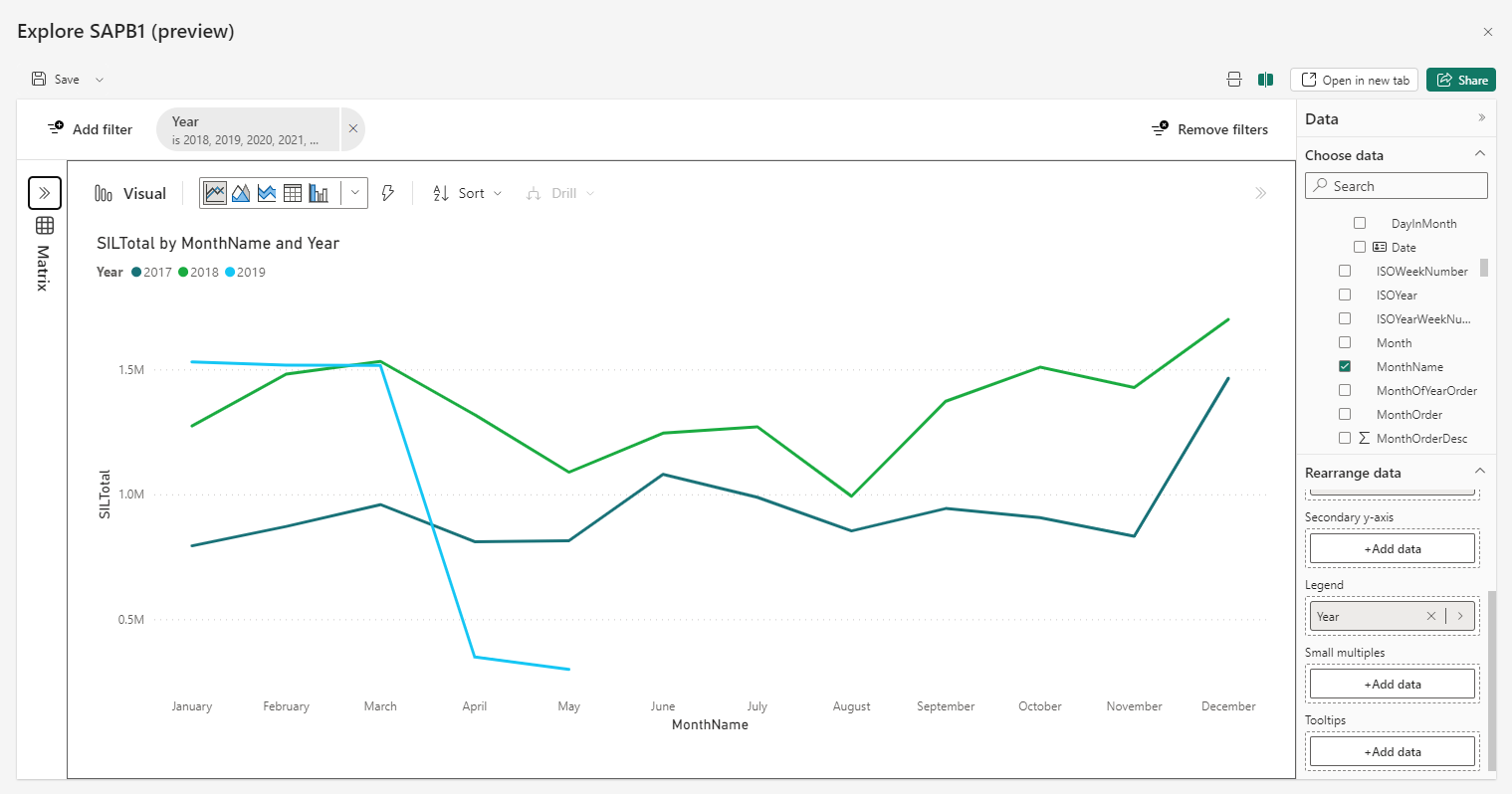
Explore Functionaliteit
De functionaliteit van de explore functie is beperkt tot het creëren van een matrix met bijbehorende visual. Alle visuals die in Power BI beschikbaar zijn ook hier beschikbaar. Tevens is het mogelijk om niet-standaard visuals toe te voegen net als in Power BI. De standaard opmaak van de visuals is niet aan te passen, maar dat is voor het ad-hoc analyseren van data ook niet nodig. Bovenin is een filterbalk aanwezig waar simpel en snel filters kunnen worden toegevoegd die op de matrix en de visual effect hebben. Het is overigens ook mogelijk om alleen de matrix of de visual weer te geven.
Mocht de analyse die gemaakt is toch vaker nodig zijn, dan kan hij worden gedeeld met andere mensen of worden opgeslagen als een rapport. De visuals worden dan als objecten aan het rapport toegevoegd en kunnen dan zoals standaard visuals in rapporten worden bewerkt.

Conclusie
Meer dan het snel maken van een matrix in combinatie met een visual is het eigenlijk niet. Het maken van een snelle analyse wordt zo wel erg makkelijk. Echter was dit ook al mogelijk door gewoon in de Power BI Service een rapport te maken op een semantisch model en dit dan niet op te slaan. Echt veel toegevoegde waarde vind ik het dus niet hebben.



