In het voorgaande blog over DWH Automation (hier) is duidelijk geworden dat arbeidsintensieve en repeterende handelingen als het opzetten van een staginglaag, of het doorvoeren van wijzigingen in kolommen over verschillende lagen heen grotendeels geautomatiseerd kan verlopen. Dit wordt al bereikt door slechts gebruik te maken van een verzameling slimme stored procedures en gedegen naming convention. Hoe zou dit verderop in het DWH proces toegepast kunnen worden, wanneer business rules om de hoek komen kijken?
De transformatieslagen voor het vullen van dimensietabellen en feitentabellen zijn namelijk heel specifiek. Dus lijken deze niet op hun plaats in automatisering van generieke zaken, zoals in de eerste blog te zien is. Toch is er nog steeds veel tijdwinst te halen door middel van het genereren van code.
Stel, data is beschikbaar in de historische staging, waarna we deze willen transformeren en dus onderbrengen in een andere structuur in de DWH laag. De business wil namelijk graag bepaalde logica toegepast zien op de data en er is besloten om dit in het DWH model te realiseren.
Laten we als versimpeld voorbeeld een STORED PROCEDURE nemen, zoals we die dan normaal gesproken zouden opbouwen. Onderstaande code laat dit zien, waarin heel veel generieke aspecten te herkennen zijn. Het enige wat niet generiek is, dat is het SELECT gedeelte met de business logica (rood omlijnd). Omdat we nieuw binnengekomen data mergen met bestaande data, is er verhoudingsgewijs veel (generieke) code nodig rondom de business logica. Als we op een later moment tien kolommen moeten toevoegen, dan zal dat niet alleen in het rode kader moeten gebeuren, maar ook binnen de drie andere delen waar de kolommen benut worden. Het lijkt vanzelfsprekend om dit handmatig te doen. Maar dat hoeft dus zeker niet. Het zou zelfs onnodig veel tijd kosten. Laat staan als een nieuwe tabel met honderd kolommen nodig is.
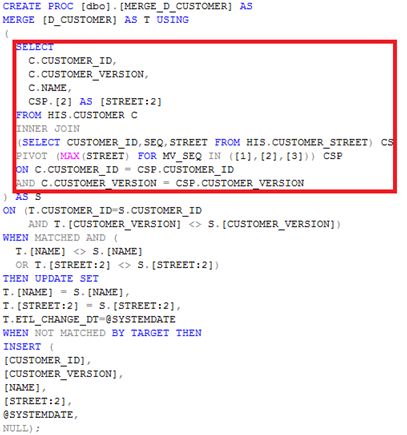
Om tijd te besparen, kunnen we het roodomlijnde gedeelte namelijk in een VIEW onderbrengen, waarna we deze VIEW aanroepen in de STORED PROCEDURE. We schiften de specifieke business logica dus als het ware uit de STORED PROCEDURE. Zie hieronder de view:
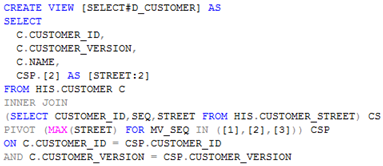
De STORED PROCEDURE moet anders worden opgezet, zodat deze de view aanroept, in plaats van de hele SELECT clause. Hiermee wordt exact hetzelfde resultaat bereikt als met de code uit het eerste voorbeeld.

Maar biedt dit nu voordelen? Deze splitsing lijkt op het eerste gezicht extra inspanning te kosten. Immers, de aanroep van de VIEW is juist meer code. Maar… we kunnen wederom gebruik maken van het INFORMATION_SCHEMA van de database om alle (!) STORED PROCEDURES voor de dimensies volledig automatisch te genereren! Zie hiervoor ook het eerdere blog. Het enige werk wat dus elke keer inspanning behoeft, dat is de uitwerking van de business logica. De overige technische noodzakelijkheden kunnen dus volledig geautomatiseerd worden!
Er zitten natuurlijk wel randvoorwaarden aan deze opzet. De structuur van de doeltabel en de view moeten bijvoorbeeld 1 op 1 overeenkomen. En nadat de view is aangepast, zal de STORED PROCEDURE opnieuw gegenereerd moeten worden. Overigens, het gebruik van een VIEW zoals in het voorbeeld kan in eerste instantie zeer traag zijn. Door de juiste mechanismen toe te passen, zal dit echter volledig gecompenseerd kunnen worden. En die “truukjes” hoeven slechts eenmalig in de master STORED PROCEDURES te worden ondergebracht, waarna dit voor alle dimensie tabellen gegenereerd kan worden!
Nog een laatste nuance is dat de business logica ook verder kan reiken dan het SELECT deel uit het voorbeeld. Stel, men wil helemaal niet STREET:2 vergelijken binnen het ogenschijnlijk generieke MERGE onderdeel. Dan is de overgebleven code helemaal niet zo generiek meer, toch? Welnu, het INFORMATION_SCHEMA dat ten grondslag ligt aan de aansturing van de gegenereerde code, kan worden uitgebreid met eigen beheertabellen om zo naast naming convention te differentiëren tussen tabellen en kolommen.




